
Opis szkolenia
Rosnąca ilość danych w organizacjach w większości przypadków nie idzie w parze z ich jakością. Różne źródła danych, różne formaty, różni właściciele, niespójne procesy zarządzania danymi, to wszystko generuje rosnący problem z jakością informacji i jakością decyzji podejmowanych na ich bazie. W ramach szkolenia uczestnicy poznają procesy biznesowe związane z zarządzaniem danymi, ustalaniem odpowiedzialności za dane oraz mierzenia jakości informacji prezentowanych na raportach.
Zakres szkolenia
- Znaczenie, dobór i przetwarzanie danych
- Definiowanie jakości danych
- Ocena jakości przechowywanych danych
- Poprawa jakości danych
- Profilowanie danych
- Praktyczne przykłady oceny jakości zbioru danych
- Systemy wspomagające utrzymanie jakości danych: MDM, DQM i inne
- Demonstracja systemu wsparcia jakości danych i jego wpływ na jakość informacji
- Dyskusja nt. nabytej wiedzy i doświadczeń Cogit z wdrożeń
Odbiorcy szkolenia
- Osoby odpowiedzialne za zarządzanie danymi w firmie,
- Chief Data Officer,
- członkowie zespołów kompetencyjnych Business Intelligence,
- architekci hurtowni danych i rozwiązań Business Intelligence
- oraz inne osoby, dla których jakość danych jest kluczowym elementem pracy.
Forma szkolenia
Szkolenie jest zaplanowane w formie warsztatów (wykłady teoretyczne połączone z ćwiczeniami praktycznymi). Czas trwania: 2 dni po 8 godzin lekcyjnych po 45 minut.
W przypadku szkoleń dedykowanych możliwe jest rozszerzenie lub skrócenie zakresu merytorycznego.
W trakcie szkolenia uczestnicy zostaną zaznajomieni z teoretycznymi podstawami każdej z sekcji szkolenia a większości tychże sekcji będą oni mogli utrwalić nabytą wiedzę w formie ćwiczeń wykonywanych na indywidualnych stanowiskach komputerowych (zapewniamy sprzęt).
Program szkolenia
1. Ogólne informacje o znaczeniu, doborze i przetwarzaniu danych
W pierwszej części szkolenia przedstawione zostaną założenia teorii informacji w zakresie opisywania procesów biznesowych poprzez dane; definicja danych; ich znaczenie dla realizacji bieżących i przyszłych potrzeb biznesowych.
Zostanie także omówione pochodzenie danych ze względu na źródło (ręczne wprowadzanie, import (push vs pull), integracja z innymi systemami, transformacje wewnętrzne, inwentaryzacja biznesowa i techniczna (metadane) oraz ocena użyteczności danych vs wymagania biznesowe.
Pierwsza sekcja zakończy się przeglądem systemów przechowywania danych: lokalne i rozproszone bazy danych, pliki tekstowe, arkusze kalkulacyjne, XML, Big Data, relacyjne, wielowymiarowe i dokumentowe bazy danych, EAV.
2. Definiowanie jakości danych
W trakcie tej sekcji uczestnicy zapoznają się z podstawowymi wiadomościami o procedurach opisu danych względem informacji, jakie mają przechowywać:
- Typy danych, dziedziny, zakresy
- Sekcja ta zakończy się ćwiczeniami w zakresie prezentowania typów danych oraz każdego z omówionych typów błędów danych.
Sekcja ta zakończy się ćwiczeniami w zakresie prezentowania typów danych oraz każdego z omówionych typów błędów danych.
3. Ocena jakości danych
Niniejsza sekcja pozwoli uczestnikom na szersze spojrzenie na jakość danych jako część procesu ich zarządzania poprzez pracę z całymi zestawami danych (w porównaniu z poprzednią sekcją skupioną na pojedynczych atrybutach). Jej temat obejmie swoim zakresem:
- Definiowanie „mierzalności” jakości danych (miary jakości, umowne zakresy poprawności)
- Raportowanie pomiarów jakości danych
- Analizowanie błędów i badanie przyczyn złej jakości danych
Mając wiadomości o tworzeniu analizy jakości danych uczestnicy zbudują przykładowy raport jakości danych.
4. Zarządzanie danymi w organizacji
W tej krótkiej części zostaną zaprezentowane podstawy budowy procesów zarządzania danymi od strony biznesowej
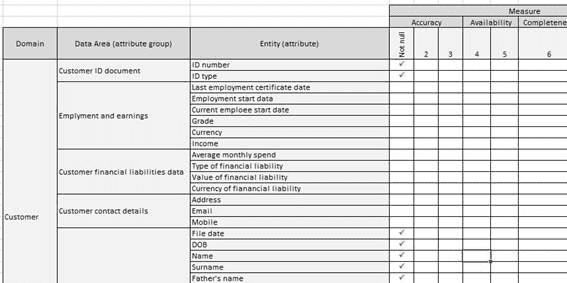
- Katalog danych, grupowanie atrybutów, encje i pochodzenie ich atrybutów, ocena atrybutów pod kątem kryteriów jakości danych (dokładność, dostępność, kompletność, rozkład, duplikacja, itp.)
- Formalne zarządzanie danymi jako aktywami wewnątrz organizacji (dostępność, użyteczność, integralność oraz bezpieczeństwo)
- Rola data stewarda
Na zakończenie uczestnicy zapoznają się z przykładami arkuszy klasyfikacji danych jako narzędzi pomocnych w zarządzaniu informacją.
 |
 |
5. Poprawa jakości, metadane oraz profilowanie danych
Ze względu na niekiedy ograniczoną możliwość korekty danych w systemach źródłowych należy tę operację wykonać w trakcie przetwarzania danych. Niniejsza część szkolenia skupi się na metodach zwiększania jakości danych. Będą to m.in.:
- Profilowanie danych
- Ocena i walidacja
- Strategia oczyszczania
- Oczyszczanie i wzbogacanie
- Monitorowanie
Uczestnicy będą także mieli okazję sami przyjrzeć się przykładowemu narzędziu, które pozwala na dostarczanie kompleksowych informacji o danych, w tym o ich jakości.
6. Systemy wspomagające utrzymanie jakości danych: MDM, DQM
W tej części słuchaczom zostaną zaprezentowane dwa rodzaje aplikacji wspomagających utrzymanie jakości danych:
- Master Data Management – zarządzanie „złotym rekordem” w organizacji
- Data Quality Management – automatyczna korekcja danych
7. Dyskusja nt. nabytej wiedzy i doświadczeń Cogit z wdrożeń
Ostatnia część szkolenia obejmie pytania i praktyczne podejście do kwestii jakości danych w różnego rodzaju organizacjach (m.in. instytucjach finansowych).
Prowadzący szkolenie

Hubert Kobierzewski
Hubert pracuje w firmie Cogit jako BI Practice Lead. Pomaga klientom zebrać ich dane oraz przekonwertować je w wartościowe informacje. Od lat związany z tematyką szeroko rozumianych rozwiązań Business Intelligence...
Zobacz profil →